Markov Decision Process 是强化学习的核心,帅气的 David 说所有的强化学习问题都可以转化为 MDP,即就像 RBM 是深度学习的发源地一样,MDP 是整个强化学习的基础。而和名字一样,我们需要首先理解 Markov 和 Decision(Reward),接下来会从 Markov 过程到 Markov 过程加上 Reward 之后的马尔可夫奖励过程,最后引入 Bellman 方程,通过解 Bellman 方程的方式深入了解到底何为决策。
第三课 动态规划寻找最优策略
这节课是接着第二节课的,个人对这节课的总结只有一句话对 Bellman 方程多次迭代能得到最优策略和最大价值。课程开始的时候,David 大佬答大体讲了下什么是动态规划,这个想必大家都很熟悉了,就不赘述了。我们仔细想 Bellman 方程其实是完美的复合了动态规划的要求的条件的。所以我们就有了以下的内容。
第一课 强化学习简介
强化学习是什么
强化学习在不同领域有不同的表现形式:神经科学、心理学、计算机科学、工程领域、数学、经济学等有不同的称呼。
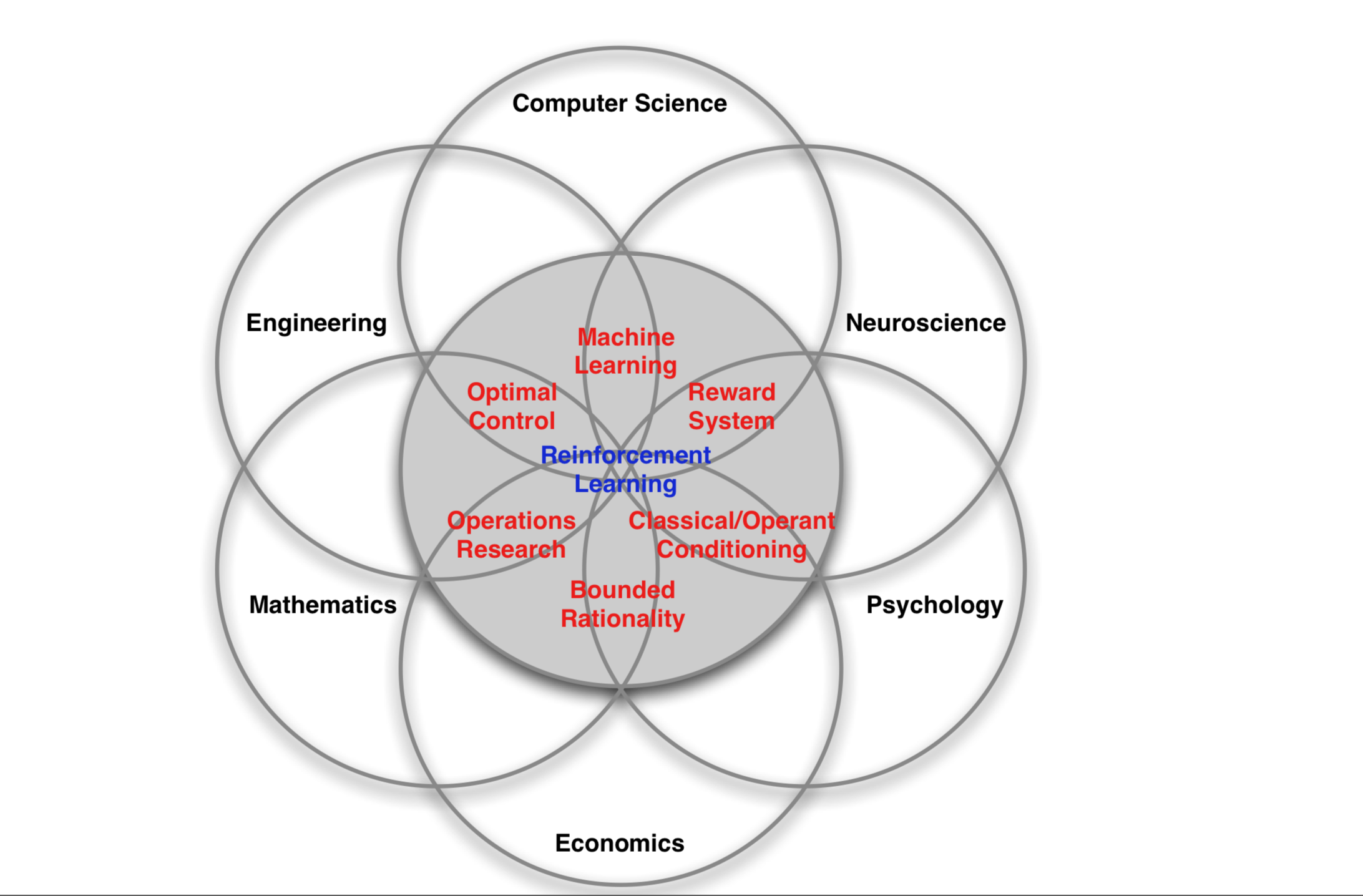
而强化学习是单独的一个机器学习的分支,他不属于监督学习,也不属于无监督学习。他的特点如下:
- 没有监督数据、只有奖励信号
- 奖励信号不一定是实时的,很可能会延后很多
- 时间(序列)是一个关键因素
- 当前的行为会影响后续的数据
注:之前的深度学习,机器学习这些是基于数据的,而强化学习则是基于模拟实验的。
Tensorflow进阶之数据导入
不同格式的数据的导入
Numpy 数据的导入
这种导入非常直白,就是使用 Numpy 把外部的数据进行导入,然后转换成 tf.Tensor ,之后使用 Dataset.from_tensor_slices()。就可以成功导入了。简单的案例如下:
1 | |
上面的简单的实例有一个很大的问题,就是 features 和 labels 会作为 tf.constant() 指令嵌入在 Tensorflow 的图中,会浪费很多内存。所以我们可以根据 tf.palceholder() 来定义 Dataset,同时在对数据集初始化的时候送入 Numpy 数组。
1 | |
python数据可视化之 seaborn
简介
Seaborn 是一个数据可视化的库,主要用来生成热力图的,详情查看它的官网。这个工具一定要混合 matplotlib 来使用,我们在做好图之后还是必须要用 plt.show 才能展示图片,同时图片的布局也是靠 matplotlib。
python 多进程并发
前言
最近在处理大数据相关的东西,数据动辄上百万,还不能用 GPU 加速,于是开始动起了多进程的念头。众所周知,Python 的多线程是假的,不过好在开发者老大还是给我们留了一个活路,也就是进程池。这个方法的优点在于进程的并发细节完全不用我们操心,我们只需要把并发的任务仍到进程池里就好了。
python使用二进制文件存取中间变量
前言
我们经常遇到一种情况,就是废了很大的精力和时间通过程序算取的数值,在程序结束后就会被销毁,而下次再想使用则需要再算一遍。通用的存储这些值的方法为把他们以文本的方式存到文件中,之后需要的时候再读取。然而这种方式的效率实在是比较低,python 为我们提供了一个将值存储到 2进制文件的方案,其速度亲测可以快 3 倍左右。
Tensorflow 进阶之 Estimator
之前的入门部分的 Estimator介绍了如何使用预训练模型,对整体有了一个直观的感受感受。在这部分中着重讲解如何创建自定义 Estimator。
Estimator 模型的简单说明
所有的 Estimator 的模型的基类为 tf.estimator.Estimator ,这意味着即便是预设置的模型其实也是用自定义模型的方式设置的。和之前介绍的使用预创建的 Estimator 的唯一区别在于,我们需要自行编写模型函数(model_fn)
Tensorflow入门之数据导入
tf.data API 简介
借助这个 API 可以较为快速的入门数据导入的部分。自定义数据输入可以说是跑任何模型必须要会的部分。学习这部分 API 是入门 Tensorflow跳不过的部分。本部分和之前的 Tensorflow 部分一样,主要是筛选自官方教程,意在跳出自己认为核心的入门内容,抛去复杂的细节,以求快速入门。
Tensorflow 入门之Keras
Keras 官宣特征
- 简单快速的圆形部署
- 支持 CNN 和 RNN,也支持两者结合
- 同时支持 CPU 和 GPU 计算。