
简述
这个课,简单的来说就是说,word2vec 除了之前的 skip-gram 算法,还有一个传统的算法使用基于窗口的共现矩阵来表示。他们都有缺点,于是诞生了 GloVe。
SkipGram 的进阶思考
上一个视频我们已经学了 Skip-gram 的全部思想啦,但是细心的大家肯定发现了,在 Skip-gram 算法中,它对每个文中的词都给了一个窗口来进行运算,同时预测概率的公式的分子部分是两个维度巨巨巨大的向量进行点积操作,显然到此为止,这个算法的实际应用开销太大。
于是这里引入我们在 assignment01 中要使用的 negative sampling 来实现 skip-gram。这个思想是使用一种采样子集来简化运算。具体的做法是,取除中心词和上下文外的随机几个样本作为负例,训练 binary logistic regression。简单的来说就是,让非窗口内的单词出现概率最小,窗口内的最大。
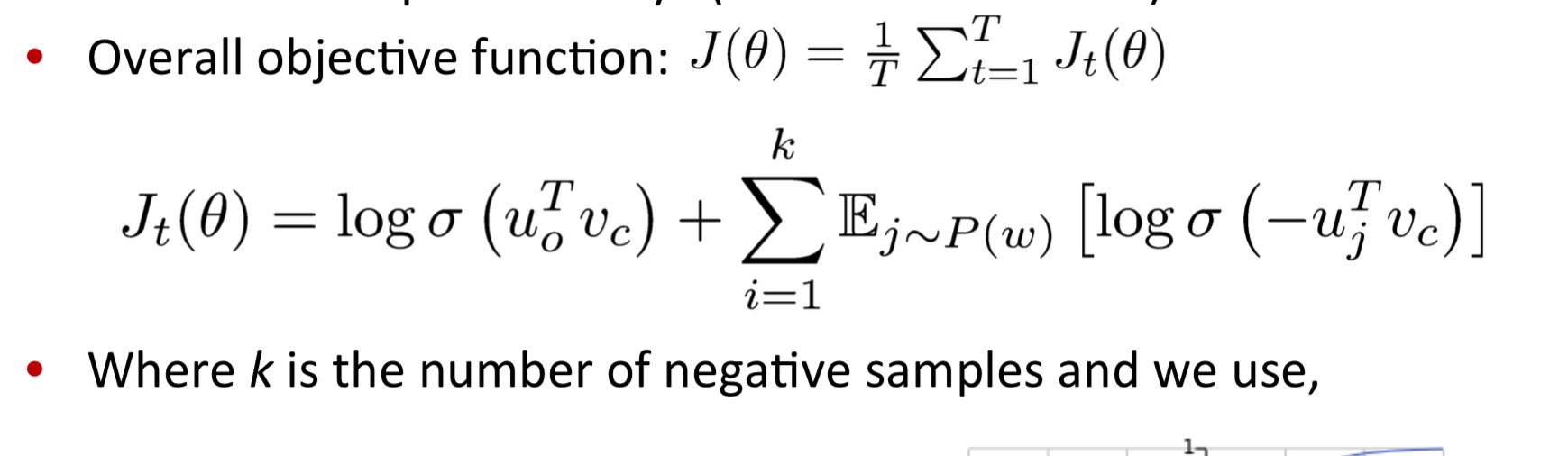
注:
- 实际应用中直接全局取随机,抽到窗口内的单词概率很小,这是帅小哥的原话。
- 其中 $P(w)$ 为 unigram 分布,旨在总是缓解出现总是抽到出现频率特别多的词的情况
- 其中 $\sigma$ 是我们的常用的 sigmoid 函数,这里用了它另一个性质 $\sigma(-x) = 1- \sigma(x)$
另一个方法
我们可以看到 word2vec 将窗口作为训练的单位,每移动一次都需要计算一次参数,那么我们是否能用单词在窗口内出现的频次来构建参数呢。 答案是肯定的,在 word2vec 之前很久,就已经出现了许多得到词向量的方法,这些方法是基于统计共现矩阵(co-occurrence matrix)的方法。 如果在窗口级别上统计词性和语义共现,可以得到相似的词。如果在文档级别上统计,则会得到相似的文档(潜在语义分析LSA)1。
Window based co-occurrence matrix
样例样本:(window = 1)
- I like deep learning
- I like NLP
- I enjoy flying
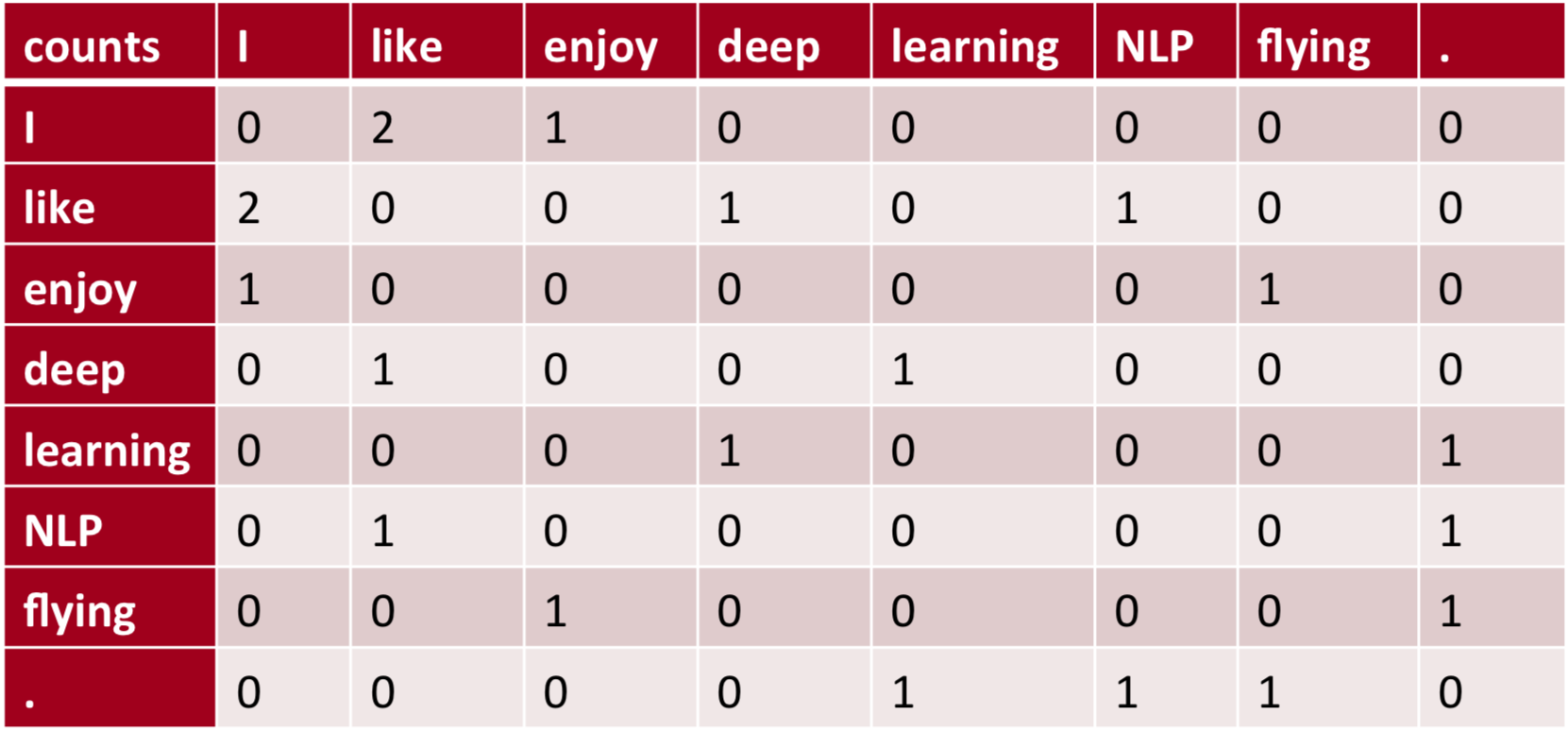
虽然生成方式很简单,但是它的局限性也很明显:
- 要加入新的单词的时候,矩阵的维度都需要改变
- 矩阵的维度特别大
- 矩阵特别稀疏(所以提到了降维度)
解决方案:
- 使用 SVD 进行降维处理
- 限制高频词的频次,或者干脆停用词
- 根据与中央词的距离衰减词频权重
- 用皮尔逊相关系数代替词频
使用 SVD 存在的缺陷:
- 很难加入新词或文本
- 和其他的 DL 的训练思路不同,很难作为下游的模型的输入
- 计算维度太高
Count based vs direct prediction
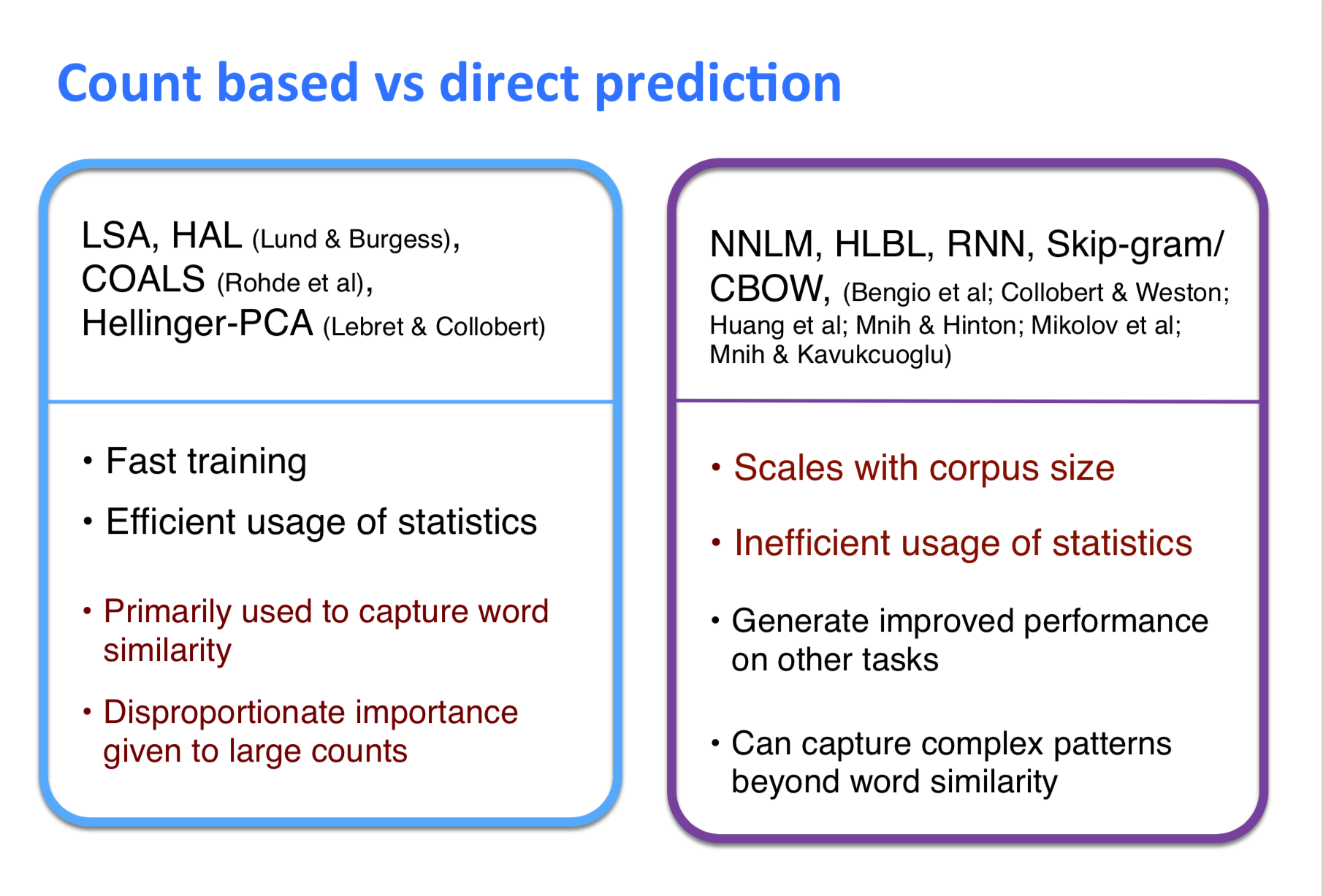 注:红色的部分是缺点
注:红色的部分是缺点
锵锵!综合两者的算法:GloVe
GloVe 目标函数
\[J(\theta) = \frac{1}{2}\sum_{i,j=1}^w f(P_{ij})(u_i^Tv_j - logP_(ij))^2\]其中 $P_(ij)$ 是两个词共同出现的频次, $u$ 和 $v$ 是共现矩阵中的行和列向量 $f$ 做了一个阀值,不让高频词的频率太高。
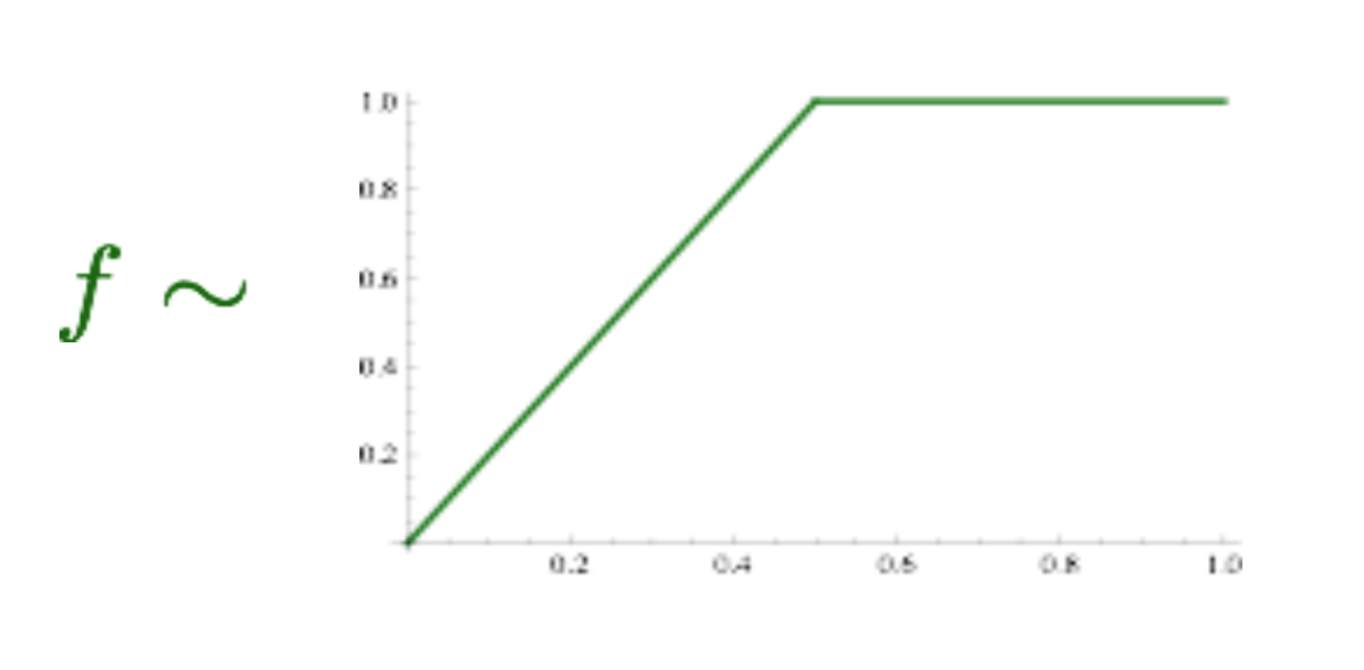
注: - 最终得到的词向量一般是 $u+v$ - 第二部分是让他们的内积更加接近真实值
优点
- 训练的很快
- 可扩展性高
- 可以在小训练集上也有不错的表现
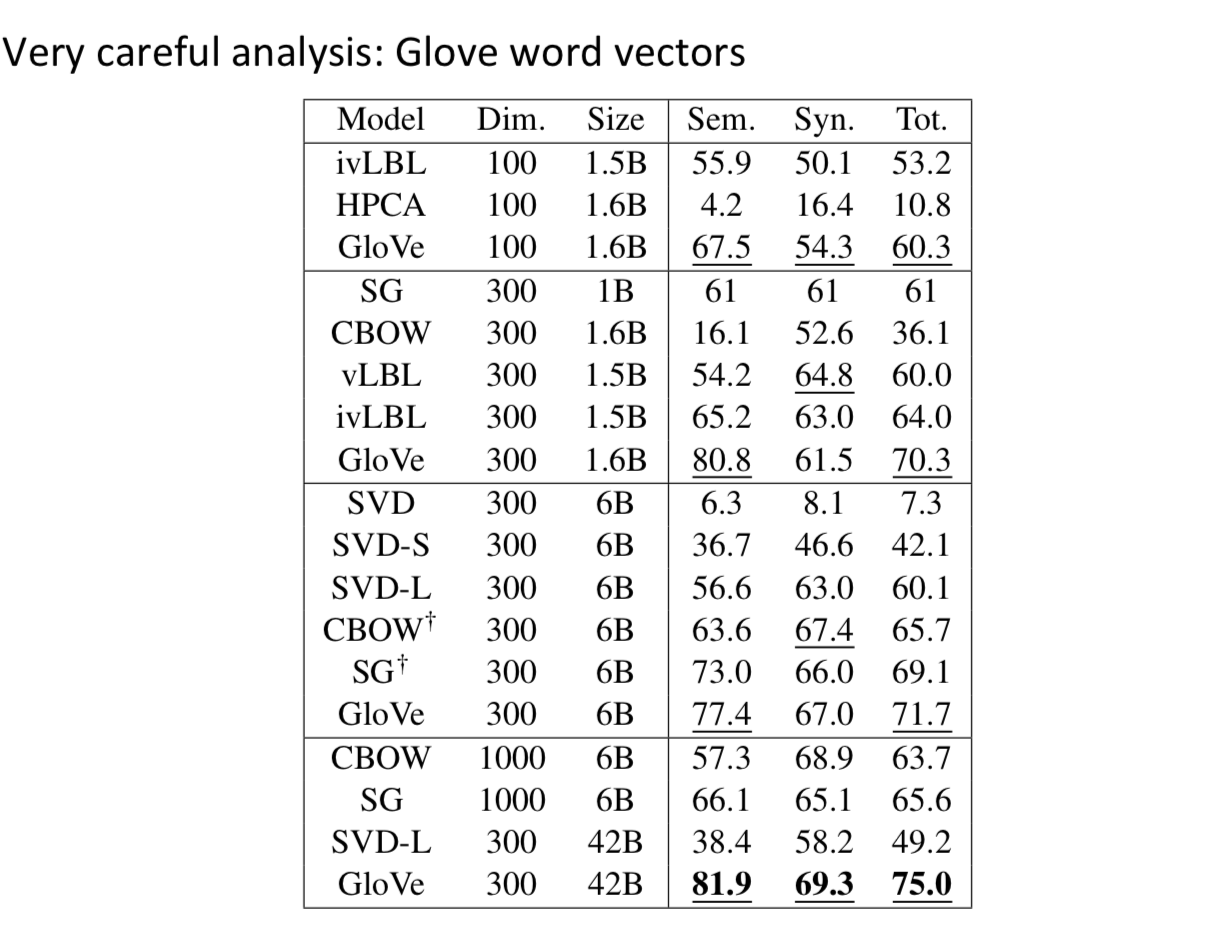 注1:GolVe 显著好于其他,但是维度不一定越高越好。不过数据量越多越好。
注1:GolVe 显著好于其他,但是维度不一定越高越好。不过数据量越多越好。
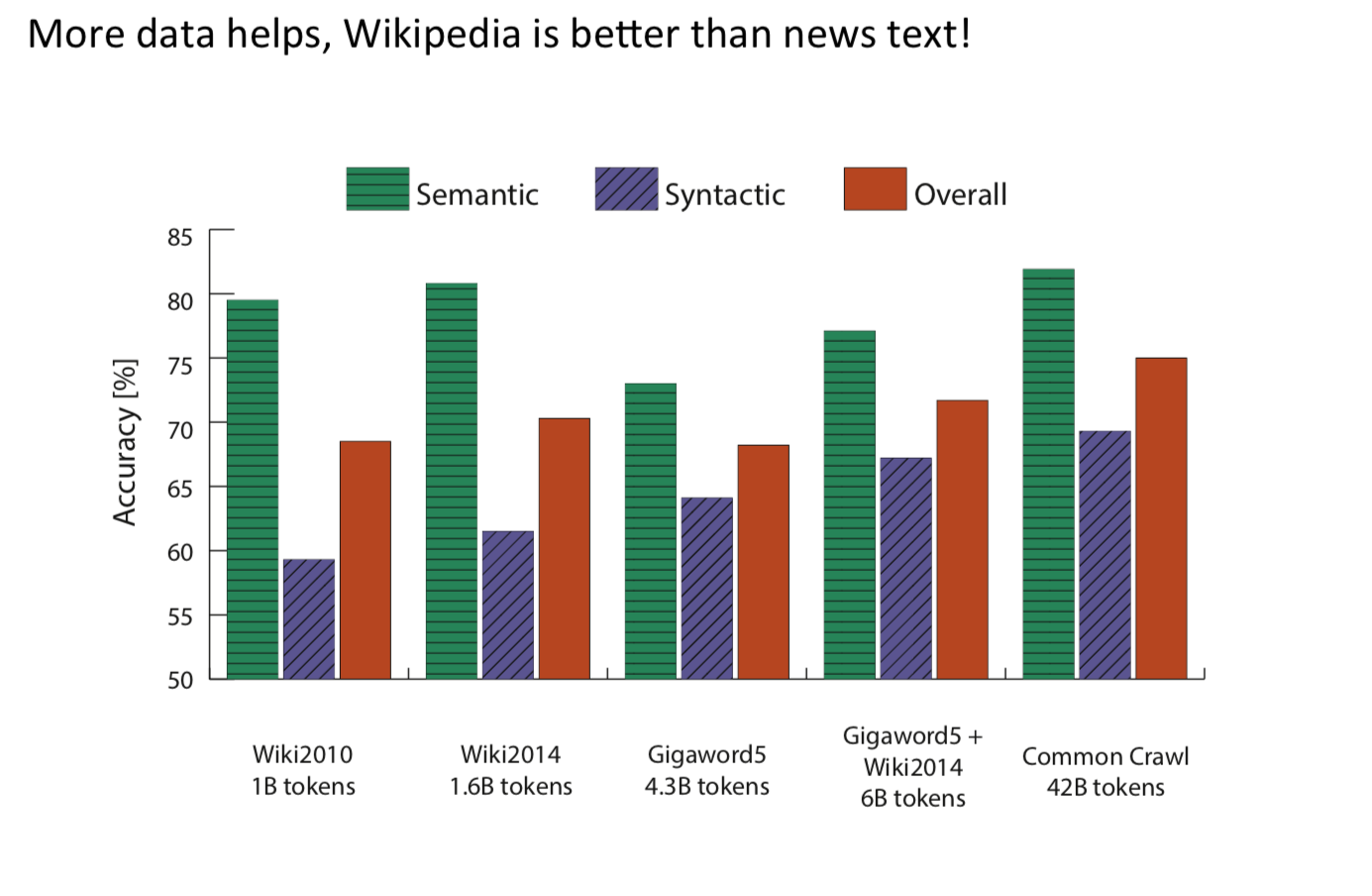 注2:wiki 的词库效果好于新闻的效果
注2:wiki 的词库效果好于新闻的效果
评测方案
评测方向有两个,Intrinsic 和 extrinsic:
- Intrinsic
- Evaluation on a specific/intermediate subtask
- Fast to compute
- Helps to understand that system
- Not clear if really helpful unless correlation to real task is established
注:可以理解为实验理想环境,不确定真实情况是否有效
- Extrinsic:
- Evaluation on a real task
- Can take a long time to compute accuracy
- Unclear if the subsystem is the problem or its interaction or other subsystems
- If replacing exactly one subsystem with another improves accuracy
注:可以理解为实际环境,耗时长,需要至少两个 subsystems 同时证明。这类评测中,往往会用 pre-train 的向量在外部任务的语料上 retrain2。
其他有意思的
- 做展示图的时候,曲线需要收敛了才行,帅小哥说图只截出了趋势会扣分的(笑
- 视频中还谈了谈一些适合word vector的任务,比如单词分类。有些不太适合的任务,比如情感分析。课件中则多了一张谈消歧的,中心思想是通过对上下文的聚类分门别类地重新训练3。
