这节课是接着第二节课的,个人对这节课的总结只有一句话对 Bellman 方程多次迭代能得到最优策略和最大价值。课程开始的时候,David 大佬答大体讲了下什么是动态规划,这个想必大家都很熟悉了,就不赘述了。我们仔细想 Bellman 方程其实是完美的复合了动态规划的要求的条件的。所以我们就有了以下的内容。
Iterative Policy Evaluation
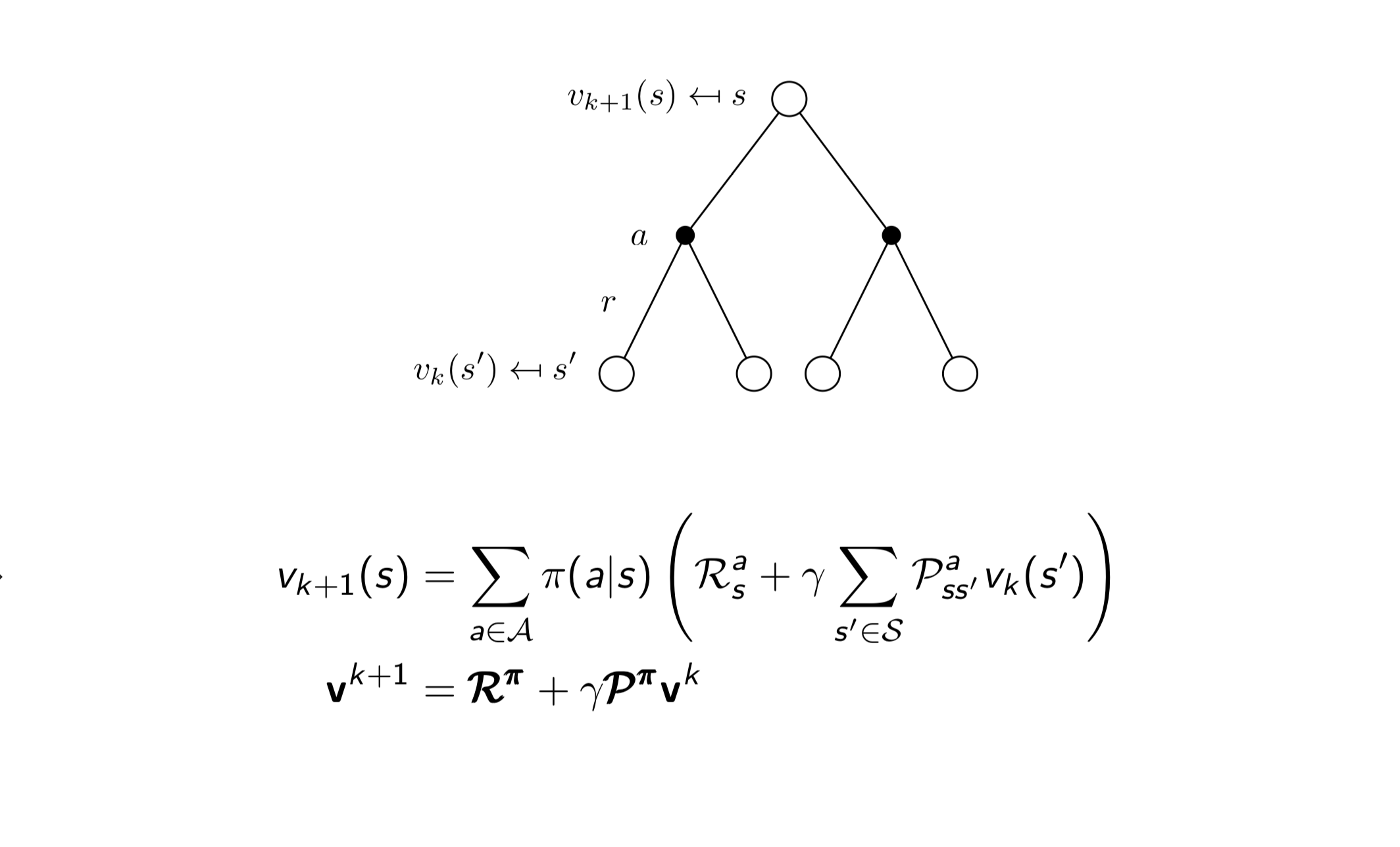 简单的来说就是重复迭代上述的过程,最终 $v(s)$ 会收敛到最大值,这样子我们就能评估当前选择的 Policy $\pi$ 好不好了。下图为算法收敛的过程。
简单的来说就是重复迭代上述的过程,最终 $v(s)$ 会收敛到最大值,这样子我们就能评估当前选择的 Policy $\pi$ 好不好了。下图为算法收敛的过程。
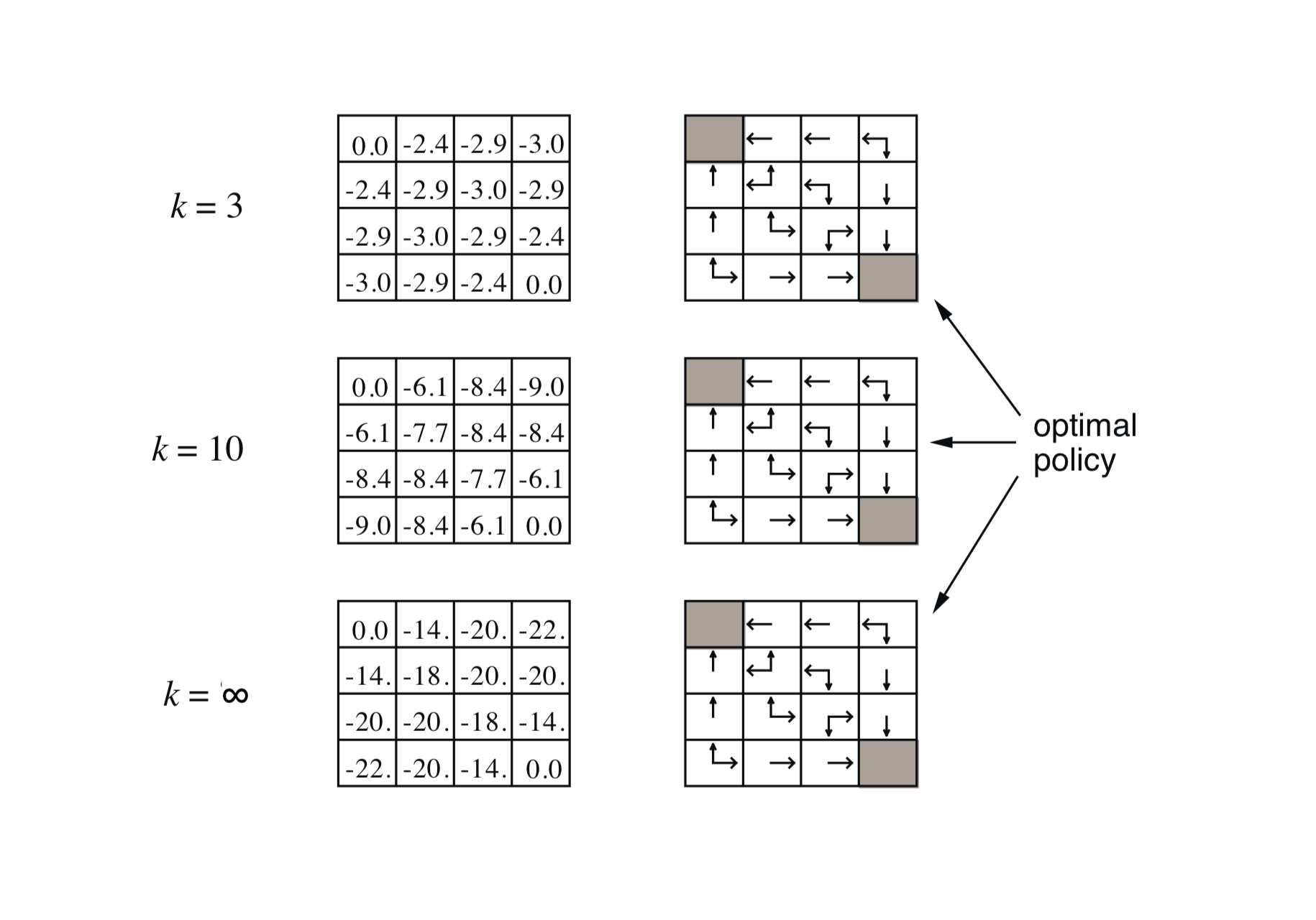
How to Improve a Policy
有了 Policy 的评估之后,直觉上我们就有了下面的算法,就是每个步骤都看看当前策略候选集中的最优策略是什么,并选择最优的策略。
 由于整个算法最终会收敛到唯一的最优策略和最大 value,所以我们就不停的迭代上述步骤就好啦。
由于整个算法最终会收敛到唯一的最优策略和最大 value,所以我们就不停的迭代上述步骤就好啦。
注:收敛是因为每次贪婪的选择最优策略一定会导致下一步的结果更好,同时 MDP 保证了其最优策略等价于最优 value。
总结
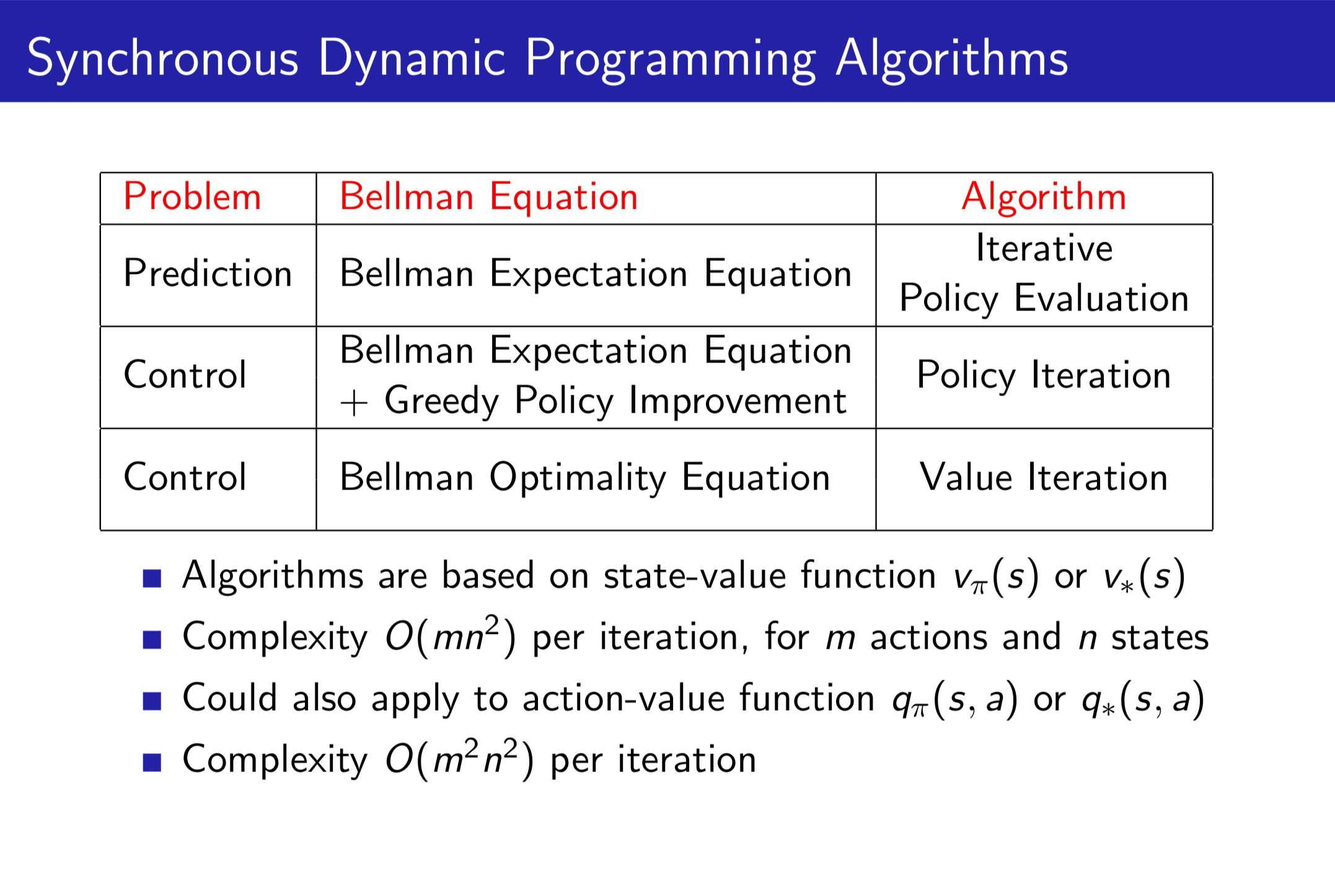 可以这么理解,Value Iteration 是为了评估目前可选的 Policy,Policy Iteration 就是根据评估找出当前最好的 Policy。之后重复上述两个步骤就能得到最优 Policy。
可以这么理解,Value Iteration 是为了评估目前可选的 Policy,Policy Iteration 就是根据评估找出当前最好的 Policy。之后重复上述两个步骤就能得到最优 Policy。
注:之后其实还讲了异步动态规划、 采样更新、近似动态规划,但是我们实际很少使用这些,所以就不在这里提了。