强化学习是什么
强化学习在不同领域有不同的表现形式:神经科学、心理学、计算机科学、工程领域、数学、经济学等有不同的称呼。
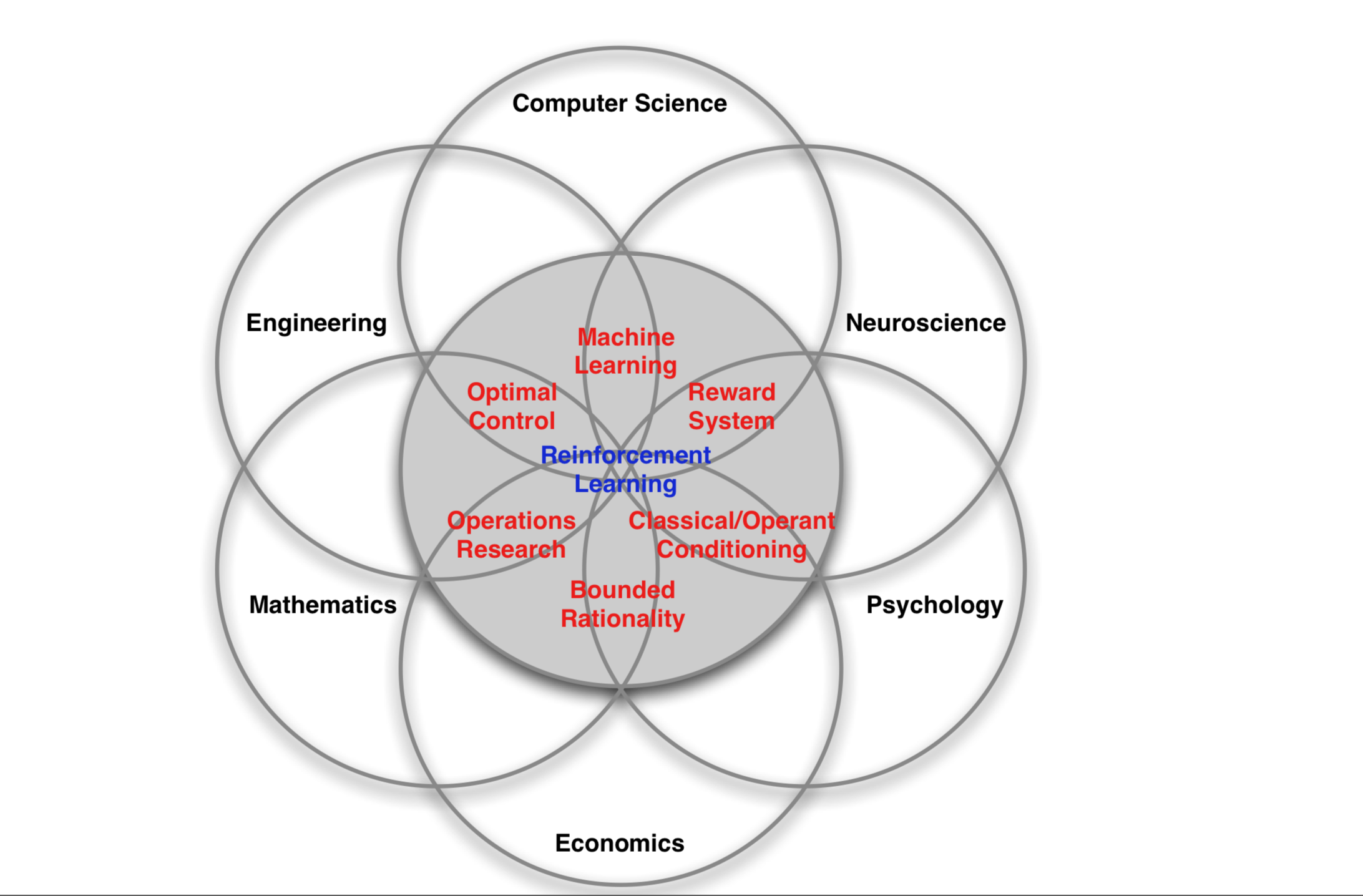
而强化学习是单独的一个机器学习的分支,他不属于监督学习,也不属于无监督学习。他的特点如下:
- 没有监督数据、只有奖励信号
- 奖励信号不一定是实时的,很可能会延后很多
- 时间(序列)是一个关键因素
- 当前的行为会影响后续的数据
注:之前的深度学习,机器学习这些是基于数据的,而强化学习则是基于模拟实验的。
强化学习问题的组成
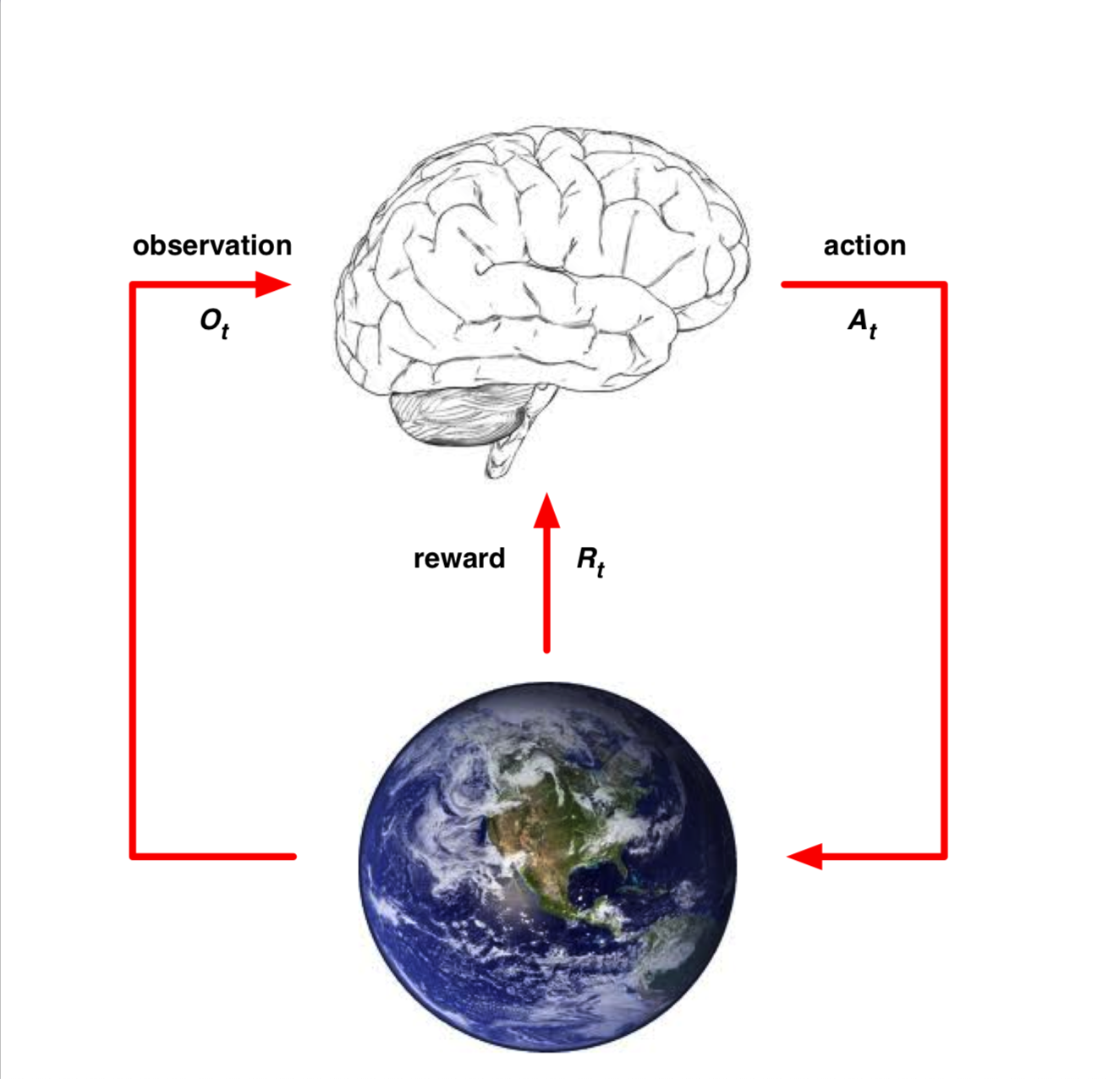
奖励 Reward
$R_t$ 是一个信号的反馈,是一个标量,而个体的工作就是最大化奖励总和(长期收益最大)。小哥说这个奖励用标量就已经足够了。
Agent & Environment
首先要注意的是智能体是不能直接得到环境的信息的。只能通过观察得到 $t$ 时间的观察评估 $O_t$ ,之后根据观察的结果选择行为 $A_t$,最终环境给智能体一个奖励信号 $R_{t+1}$。
而环境则可以接受智能体的动作,并以此更新环境。同时也能反馈个诶智能体奖励信号 $R_t$
状态和历史
历史是一个观测、行为、奖励的序列,这个序列如果全部记录下来的话太耗资源了。所以希望使用状态来表示已有的信息。这个是通过 Markov 的性质实现的。
环境状态
是环境的私有呈现,包括环境用来决定下一个观测/奖励的所有数据,通常对个体并不完全可见,也就是个体有时候并不知道环境状态的所有细节。即使有时候环境状态对个体可以是完全可见的,这些信息也可能包含着一些无关信息。
而环境是否可观测,则是区分强化学习算法的一种分类方式:
- 完全可观测环境 这种问题可以看做一个 Markov Decision Process。
- 部分可观测环境
- 用个体已知的概率分布来预测
- 使用 RNN
智能体状态
包含智能体可以使用的、决定策略使用的所有信息。一般是一个历史的函数 $S_t^a = f(H_t)$
信息状态
包括历史上所有的有用的信息,个人直观的感觉为是用在在智能体状态的一部分。
强化学习智能体
主要成分
- 策略 Policy 通过当前状态决定选择哪个动作,即输入是状态,输出是动作。
- 价值函数 Value Function 对未来的奖励的预期,用于评价当前状态的好坏程度。
- 模型 Model 用于对环境的建模
强化学习智能体的分类
- 仅基于价值函数的 Value Based:在这样的个体中,有对状态的价值估计函数,但是没有直接的策略函数,策略函数由价值函数间接得到。
- 仅直接基于策略的 Policy Based:这样的个体中行为直接由策略函数产生,个体并不维护一个对各状态价值的估计函数。
- 演员-评判家形式 Actor-Critic:个体既有价值函数、也有策略函数。两者相互结合解决问题。
此外,根据个体在解决强化学习问题时是否建立一个对环境动力学的模型,将其分为两大类:
- 不基于模型的个体: 这类个体并不视图了解环境如何工作,而仅聚焦于价值和/或策略函数。
- 基于模型的个体:个体尝试建立一个描述环境运作过程的模型,以此来指导价值或策略函数的更新。
强化学习的矛盾
探索 Exploration 和利用 Explotiation,简单的来说就是我们已有一个最优策略,如果不改变的话收益是已知的,而探索的结果是不确定的收益可能增加也可能减少。就和我们人类做决策一样,如何平衡这种矛盾也是强化学习中的一个很有趣的问题。