
简单声明
本笔记为 CS224n 课程在学习过程中留下的笔记。整体风格以简洁为主,尽量去掉不必要的背景知识说明,只留下个人觉得最重要的内容以供日后参考回忆。其中部分内容为了巩固英语,可能会因为方便采用英文记录。其中许多内容来源于学习过程中参考的博客内容,这些会在末尾的参考链接中汇总出来。
课程先决条件
- Python基础知识
- 高等数学、概率论、线性代数知识
- 基础机器学习算法
- 梯度下降
- 线性回归
- 逻辑回归
- Softmax
- SVM
- PAC 注:斯坦福CS229 / 周志华西瓜书
本课学习收获总览
- 整体自然语言处理的流程
- 深度学习的 NLP 和之前的有什么区别
- NLP 的难点在哪里
自然语言处理的总览
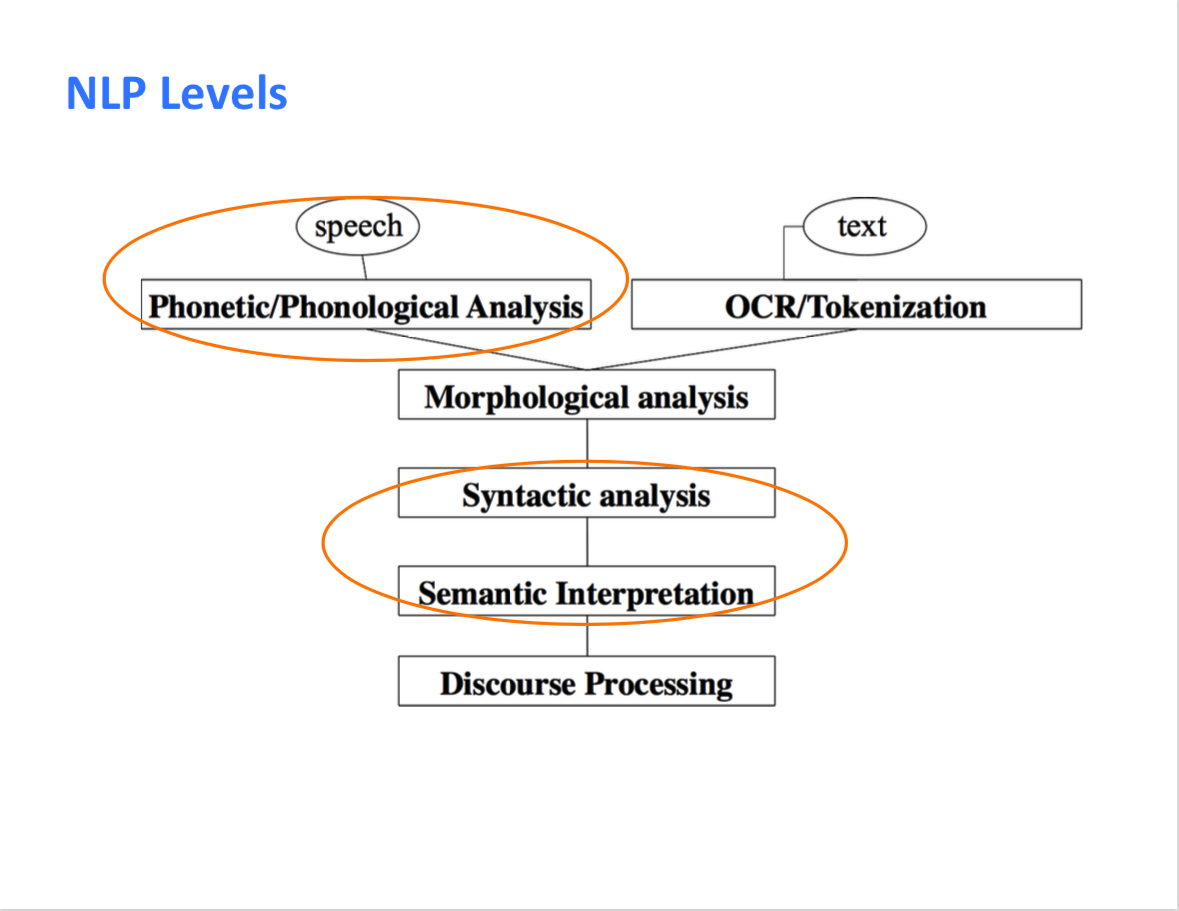
Phonetic : representing speech sounds by means of symbols that have one value only Phonology : the phonetics and phonemics of a language at a particular time Morphology:a study and description of word formation (such as inflection, derivation, and compounding) in language Syntactic:of, relating to, or according to the rules of syntax or syntactics
根据上述 Webstar 词典的翻译我们可以看到,这个整个过程很像是通信领域信号的发出和接受的过程。自然语言处理系统的输入分为两个部分,一个是文本的输入(我们暂且不谈),另一个则是语音的输入。好的,我们收到了语音,我们都知道这些语音不一定都是标准的,可能还带有方言之类的,所以我们首先要分析它,也就是第一个圈圈。之后由于单词的变形有很多,所以我们要把它们全部变换成原本的形式,也就是 Morphological Analysis 这个过程。之后,再进行语法(Syntactic)分析,最后再进行语义(Semantic Interpretation)理解。
NLP 为什么难
- Complexity in representing, learning and using linguistic/situational/world/visual knowledge
- Human languages are ambiguous (unlike programming and other formal languages)
- Human language interpretation depends on real world, common sense, and contextual knowledge
机器学习 VS 深度学习
如下图所示,传统的机器学习中很大一部分人工部分是人力的去观察你的数据,然后从中人为的提出特征,这需要消耗大量的人力,甚至这个人力还必须由有博士学位的专家才能做,而机器只是代替人类做了人类不容易做到的对算法调优的过程。
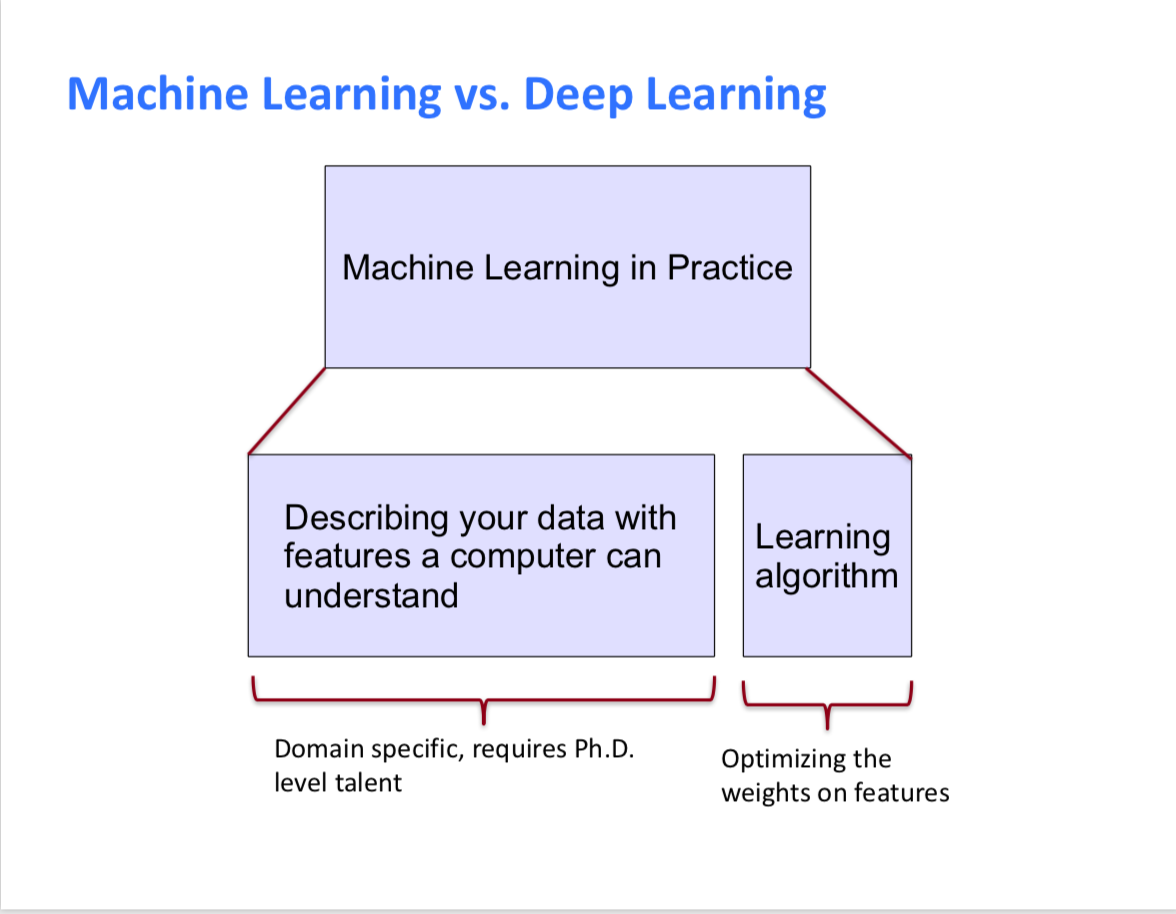
那么深度学习 (Deep Learning) 是什么呢,首先从宏观的来讲深度学习隶属于表征学习(Representation Learning),即特征学习(Feature learning)。正如其名,表征学习就是自动的从原始数据中提取分类和特征提取(feature detection)所需要的特征(representation),也就是说深度学习可以做之前机器学习中人力的那部分内容。
宏观结束了,进入微观理解, 如下图所示,深度学习中是一个多层的网络,每一层都会学习出一部分特征,然后将这些特征喂给下一层,这个学习过程可以反复的去修正 / 训练这些提出的特征,效率高。
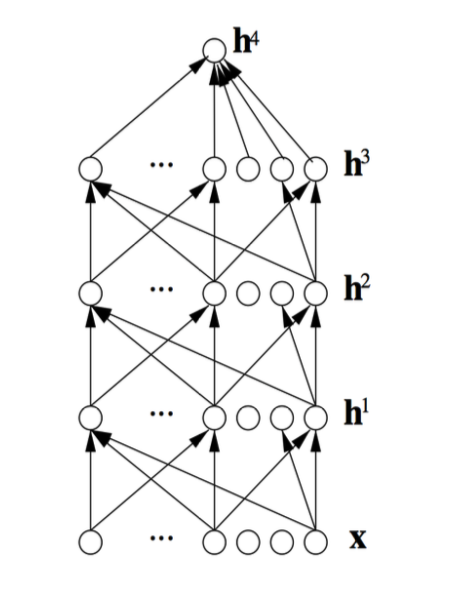
最后,大家在学机器学习的时候都知道有两种机器学习,一种是有监督学习,一种是无监督学习。深度学习两者都能做,这点是真的有点厉害。
其他总结
这堂课中有一个很重要的总结,就是在所有的 NLP 学习 Level 中,所有字的表达和其表达的含义(representations for words and what they actually represent)都是用向量(Vectors)来代替的。这点非常重要,特此记录。