序言
机器学习&人工智能&深度学习,这三个是现在经常听到的词语。一旦提到了这些都会给人一种高大上的感觉,感觉会是一种很难学会的技术。表示在下血本(突然脑抽)的情况下,剁手买了1w多的数据挖掘的网课,目前正在学习它,希望能在学习完成后揭开机器学习的面纱,争取让每个读我的博客的人都能对机器学习有一个较为全面的概念。
目前的更新顺序为课程的顺序,在整体学完之后,会按自己的理解进行一个汇总。
什么是机器学习
首先先上官方的卡内基梅隆大学的教授TomMitchell的定义。
A program can be said to learn from experience E with respect to some class of tasks T and performance measure P , If its performance at tasks in T, as measured by P, improves with experience E.
对于某给定的任务T,在合理的性能度量方案P的前提下,某计算机程序可以自主学习任务T的经验E;随着提供合适、优质、大量的经验E,该程序对于任务T的性能逐步提高。
看起来很官方的说法对吧,接下来粗略的说明是怎么回事。
一句话版本:抓了一把混着豆子的米(数据),根据你对豆子和米的特征的认识(已有经验),把豆子和米分开分别装在两个袋子里(分类),随后验收的人看你是否真的把米和豆子分开了(性能度量)。
数学版本:X*P=Y,Y是分类的类别,X是一个数据,我们找的是矩阵P能使所有的数据X都能对应到相迎的分类Y。
简单来说,机器学习就是分类器,通过学习已有的数据,得到一个数据和类别的关系,再用这个关系来对未来未分类的数据进行预测,这就是我理解的机器学习。
机器学习&人工智能&深度学习有什么区别
说到这里,有些学过深度学习的人肯定就会疑惑这个和机器学习好像一样啊,深度学习也是把图片分类啊。是的,深度学习准确的来说算是机器学习的一部分,而机器学习和深度学习又可以被人工智能所包含。只不过深度学习在图像识别和语音识别的方便有着突出的优势,而机器学习在数据挖掘,统计学习和自然语言处理方面已经有了很大的发展。
它的工作流程是什么样子
数据收集=>数据预处理(数据清洗)=>特征提取=>模型构建=>模型测试评估=>上线=>迭代
数据收集和数据清洗:可以理解为,做饭前的买菜(为模型提供训练用的有效数据,去除显而易见的无效数据)
特征提取:可以理解为,炒菜前的切菜,切的越好,炒完越好吃(即从数据中选出可能能代表数据特征的属性)
模型构建:可以理解为炒菜,用切好的菜,以一定的顺序进行翻炒(选择合适的算法来训练模型)。
模型测试评估:试吃,如果不好吃,则反思是不是切的不好,菜买的不对,或者炒的顺序不对(测试用例看是否符合标准,如果不对责重复前面的步骤)。
特别的说,训练的部分,其实就是以当前的权值运算出来的结果和已知结果对比,然后根据差距来修改权值,如此往复,使预测结果和已知结果无限接近。
算法的分类和选择
机器学习分为如下几个分类:
-
有监督学习:也就是训练用的数据是有标签的,在训练前是人工分好类的。再用训练过后的模型,对未来收到的数据进行分类,来达到预测的目的。
-
无监督学习:和有监督学习相比,训练的数据是没有分类的,在无监督学习中,就是通过学习,把这些为分类的数据进行分类,来推断出数据的一些内在结构。
-
半监督学习:训练的数据包含少量的含有标签的数据,通过这些数据来训练和分类。顾名思义就是无监督和有监督的结合。
然后从算法的角度来看,又可以分为如下三种:
-
分类:标签是整形的,是一个一个独立的离散的。分类标识的时候使用int型。
-
回归:标签是浮点型,分类是连续的而不是离散的。分类表示用float的型。
-
聚类:1,2都是有监督学习,而3则是无监督学习。
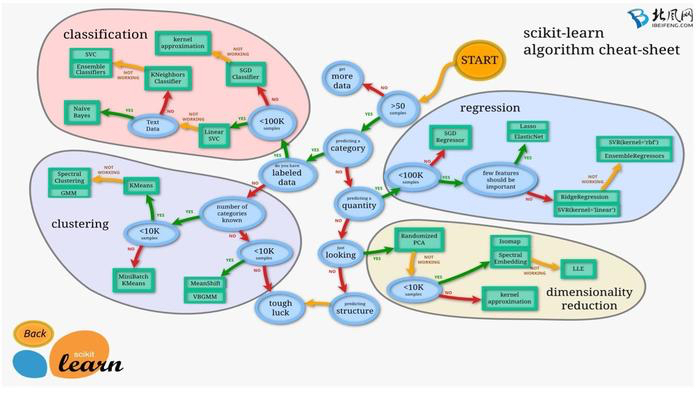
最后附上一个算法的选择图:(图很清楚只需要一点的英文水平就能看懂)